System Design: First attempt building a video-on-demand streaming architecture


Introduction
I worked on a mobile application in 2019 for live-streaming events. I was part of the engineering team, and we did not have to think about the whole streaming architecture because the client used a third-party service called Live-U. It had everything in place to manage a live stream with a GUI interface to set up transcoders, outputs, and some other technical terms familiar to people in the media and broadcast industry and was entirely managed by the media production team. We only needed to update a field in the database with the URL provided by the production team whenever they set up a live stream.
Some years later, I had to work on a streaming application again, this time not live streaming but video-on-demand. It was a newer challenge. Unlike my previous job, where I had less say in the streaming architecture, this time, I was responsible for a lot more like file storage, security, latency and overall a smooth streaming experience for the end users. Let us dive into how I set up a basic video-on-demand streaming infrastructure.
N/B: This is not a coding guide on how to set up an entire streaming infrastructure from scratch but a brief walkthrough on the system designs and architectural decisions I made as we progressed, problems faced at different stages and solutions.

We started with simple web and mobile applications that queried a REST API for data. The videos on our streaming platform at this time were mainly skits, short (5 - 15 seconds) and under 5 Megabytes. Authenticated users can query an endpoint with a movie ID to fetch and stream a movie URL. Things worked!
After a few tests, we started getting reports about stream lagging and the high cost of data consumption. Users with low-end devices or poor internet service struggled to stream the videos on our platform. I was responsible for fixing this but had a hard time deciding the right approach to take, tools or third-party services to use that would solve this problem. I was being extra careful. I did not want to introduce things that would make the setup redundant or too complex to manage in the foreseeable future.
Netflix has been a big player in the streaming business for a long time now, and it would be beneficial if we could do something on a budget (so I thought), not at the scale of Netflix, because my team and budget were a fraction compared to that of Netflix, but we could try; that was the goal.
I looked for a guide or tutorial that may aid in building something like this (on an architectural level, not just code), but I could not find many. I had to learn, unlearn, make and correct my mistakes as I progressed until we ended up with something that made sense.
NooooooooooSQL
As time passed, our needs grew, and requests for new features to the streaming application were coming in. From streaming short video skits, we had to upgrade to allow users to watch movies and series; metadata for movies was inconsistent, handling the constant schema changes as they came with a relational database became a painful task for our small team..
In another case, we needed to store and query JSON data; MySQL has fair support for JSON data types compared to NoSQL solutions like MongoDB. We migrated from MySQL to MongoDB, a NoSQL database solution. It was schema-less, easy to scale compared to our relational database and more efficient for our use case. We ended up with the following setup for the Backend.
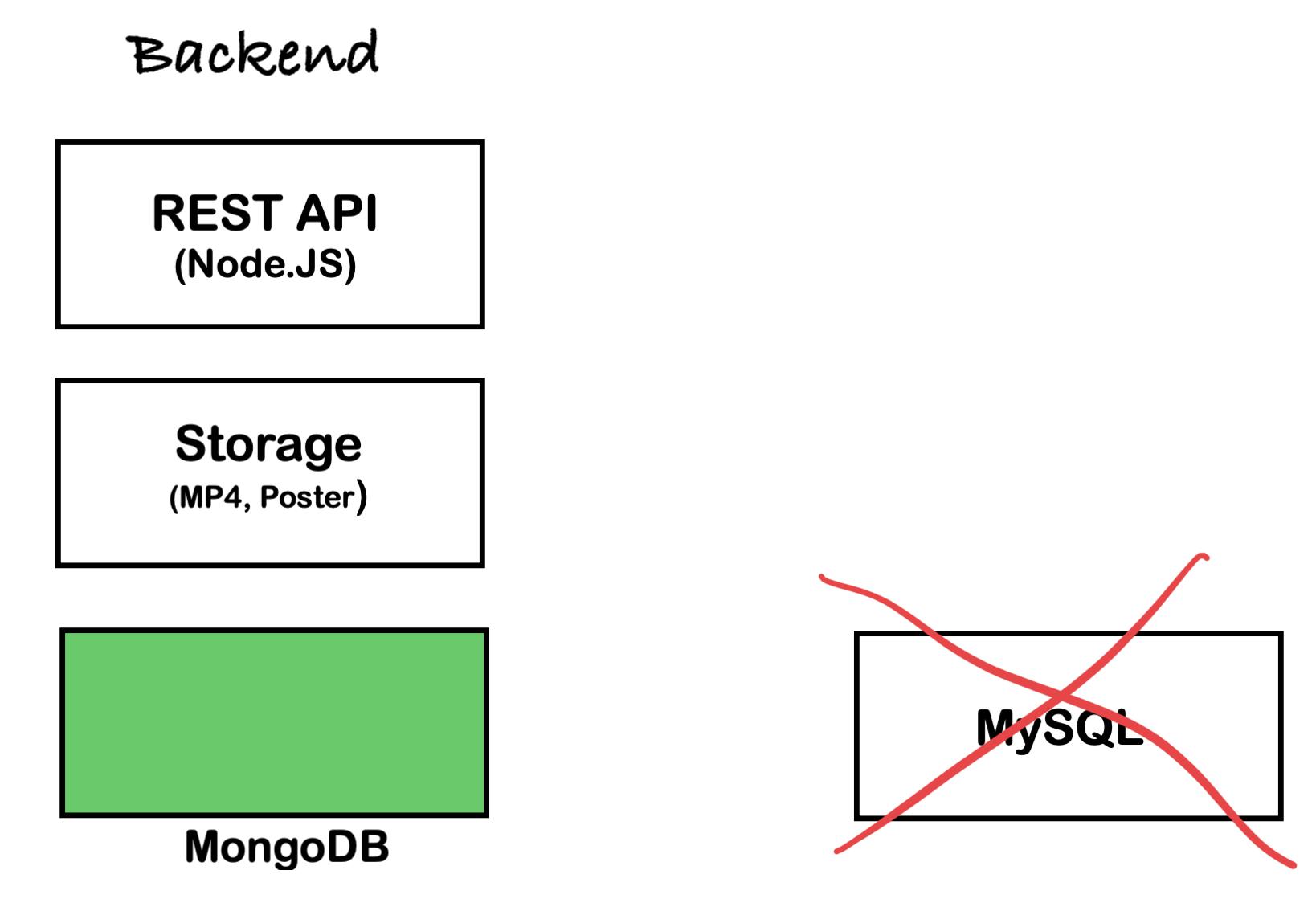
MongoDB vs MySQL: https://www.mongodb.com/compare/mongodb-mysql
Managing movie contents
A vital component of movies is their posters. Movie posters serve as a promotional and advertisement tool, with a glimpse into the plot. They can either be meaningless or give the users a mental preview of what a movie would feel like. On digital platforms, movie posters must always be available for users in the shortest time possible.
Do not judge me, but many times than I can remember, I decide if I want to watch a movie based on its poster. It could have the best title or rating, but the movie poster needs to match its plot. On digital platforms, If I try to watch a movie and do not see a movie poster, or it takes too much time to load, I may lose interest and not bother seeing the movie again.
Our in-house Storage solution could no longer handle the new requirements. We needed to fetch and transform movie posters during runtime and generate multiple variations of a single poster image from its master file.
THE PROBLEM: A single movie poster could be around 20MB in 4k quality. If you had sufficient bandwidth and a device that could handle 4k images, this would not be too much of a problem, but we should do that faster and optimally. For low-end devices with less computing power, we still want to serve the same poster but at a smaller size and quality suited for that device.
One way around this was to manually generate multiple versions of the movie poster for different devices, screen size, and quality, then upload and save a reference to their URLs in the content document. However, this would not scale; it is too much work. If we needed to target a new screen size, we would have to go back and recreate posters for all old content. A better solution would be to do this at runtime, cache the results and serve the image poster over a CDN.
After trying out a few solutions, we settled with Cloudinary. It is affordable, allows transformations via URL parameters, caches the result of the image transformation and delivers the result over its CDN.
If we had a star-wars.jpg image in our Cloudinary store that is 2500px wide, with the following URL:

To get the same image, but as 400px, we take advantage of Cloudinary URL transformation by passing the desired width in the URL:

The result of this transformed image is cached after the first transformation and served over a CDN. The next time you request the same URL, Cloudinary sends the cached version.

Bandwidth & Latency: AWS to the rescue
The demand for longer-length videos grew, and our in-house storage could no longer handle file uploads above 6GB. We had to upgrade our solution or look for alternatives better suited for this problem.
At the inception, we streamed short MP4 videos. It was not an issue for the modern devices we targeted. However, limiting streams to newer browsers was not the best idea. Users with legacy browsers should be getting the same or a similar experience. On most traditional video players, the player will have to download the entire video file before starting playback, which results in a terrible user experience for users with a slow internet connection. MP4 file streaming had to go.
What if we could split the MP4 files into chunks like we do with JavaScript modules? What if we take a 1GB MP4 file, split it into fragments of 20 seconds each (approximately 1MB per chunk), and link these fragments together like a linked list?
A solution for this already exists, known as HTTP Live Streaming (HLS). HLS is an adaptive bitrate streaming protocol developed by Apple. The adaptive bitrate streaming feature of HLS allows us to serve a single video that automatically throttles its quality depending on the internet speed and device capabilities. The HLS video player would decide on the most optimal quality to stream at any given time.
HLS files (.m3u8) are manifest files that contain metadata such as URLs of all the video fragments. When you stream an HLS video, the player parses this file and downloads each fragment in these files sequentially. HLS fragments are chunks typically representing a few seconds of a video. When stitched together, they make up an entire video. The video fragment files were smaller, resulting in faster downloads and playback, unlike our old MP4 streams.
The next step was to convert our MP4 videos to HLS. In the digital world, this process, known as transcoding, is the conversion of a digital media file from one format or codec to another.
A quick Google search for a third-party transcoding service led me to discover AWS Elastic Transcoder. I did a quick test, uploaded a video on AWS S3, created a transcoding job and waited for the generated output… IT WORKED! I configured the transcoder to generate three HLS files for every video input file. The three HLS files represented the maximum quality of the video it could stream: 480p, 720p and the default, one of 1080p or 4k.
AWS S3 worked very smoothly with the Elastic Transcoder. I figured it was the best time to deprecate our in-house Cloud Storage and switch to S3. This change would save time and effort; I would not have to write additional code that manually calls the transcoder via an API to do the job from our cloud storage server since we can automate the process with AWS cloud solutions. I configured the transcoder to automatically process jobs anytime an MP4 file gets uploaded to a specific S3 bucket. The transcoder receives an event with the MP4 file data and generates our preconfigured HLS outputs.
Lastly, I added AWS Cloudfront CDN on the S3 bucket to take advantage of cache, decrease latency and deliver content faster to the end users. With this new process in place for video uploading and transcoding, we can now fully take advantage of adaptive bitrate stream and give our users a pleasant streaming experience.

The Stream Police: Security
Everything we had set up so far with AWS was to generate an optimized stream URL for the end users. There was still a serious security flaw with the setup that had to be corrected. It was vital to take a break and stop thinking like an Engineer, the problem solver, but an exploiter, the one who finds a problem.
If I happened to be a hacker, how would I break this system to my advantage? How do I stream videos without paying or when sharing a password is not an option?
The Web and mobile applications that consumed the stream URL had authentication guards that prevented non-authorized users from making API requests to the server to fetch the stream URL of a video. However, this was not enough security since our stream URL was from an external source. Nothing stopped an authenticated user from sharing this URL with the public. A valid stream URL after Cloudfront and S3 setup looked like this:

PROBLEM: Imagine there was a critical flaw with AWS S3 that allowed hackers to exploit buckets and get a list of all the file names in a directory. Anyone with this information can stream our content directly, for free, without the need for registration on our application. The only step is to identify our Cloudfront distribution URL and append the file names from the exploit to get a working stream URL.
A solution to this problem was to use a signed URL. I also disabled access to contents if the incoming request to the distribution is not a signed URL. You can further configure access to files by setting a maximum time to live for the signed URL: signed URL should be valid for n amount of hours or days, depending on your needs.

With the getSignedURL() function, I added a small layer of security over the stream content and obfuscated the original unsigned stream URL, making it harder to guess or brute force. The new stream URL looked like this:

These additional parameters in the URL conveyed meaning to AWS CloudFront. CloudFront validates that the signed URL is valid before granting access to the content. Any modification to the original URL, changing or replacing a single character, would result in an invalid URL and CloudFront refusing access to the content. A hacker privileged enough to know the file names in our AWS S3 bucket cannot generate a valid signed URL to watch a movie except in possession of the AWS private keys that reside on the server. The signed URL approach fixed a problem, but there were more problems
An authenticated user can still share a signed URL with the public. Anyone with the signed URL can stream while bypassing the need for authentication.
HLS files are like text files that contain metadata and links to fragments that make up a video. The URL to the manifest file is signed, but the URLs of the video fragment in this file are not.
Off the top of my head, I could think of a quick way to solve this problem.
Instead of serving the direct CDN URL to the end users, why not mimic a proxy? Intercept the HLS manifest file at the request time, sign and update all the video fragment links in the text file, and send the intercepted manifest file back to the user who made the request. We can also bind the signed URLs to the user so only one device can consume a signed manifest file at any time.
This solution may work, but it seems like an additional stress load for our web server. I went online and did a quick Google search to find alternative solutions. I discovered I could use AWS Lambda to intercept the CloudFront request and sign the URLs of video fragments at the request time. An additional service that made work easier would be a plus, but this was at the expense of our budget.
Security is a complex and deep domain; you may not always get everything right. It is always good practice to assume that while you sleep, there is someone somewhere working tirelessly to exploit loopholes in what you have built. There are too many edge cases that I left out and are out of the scope of this blog post. Consulting with security and industry experts when building something at this scale is necessary. We had to do that at some point.
Services, Services & More Services
Handling unforeseen errors and edge cases that might arise on the client and server side is vital. A good example that occurred during our initial tests was recurring playback failures. Video playbacks could fail for many reasons, even when the stream URL works fine. Whenever an anomaly like this happens, we need a way to know. Frequent experiences like this with no solution may deter users from our platform. Imagine not knowing an error exists somewhere in your app that is making you lose customers.
I set up a global exception middleware on the API layer and client applications to handle errors and exceptions. At any point of failure anywhere in the application, it passes through the middleware layer. The middleware takes this error and logs it to Sentry, our error reporting platform, from which we can inspect and debug these errors as they come in, fix and deploy a release as soon as possible. Other core parts of the server used ElasticSearch as a logging service. ElasticSearch is a powerful distributed search engine, in our case, used for searching available movie contents, applications, and user and administrator events logging.
Our payment system worked differently. To make payment for any service, you would have to complete the process from a centralized platform on the web. We use a third-party service to handle payment and user subscriptions. Our payment provider uses webhooks to notify merchants about transaction status. Due to the asynchronous nature of our payment system, we needed a way to pass messages to other parts of our application when a payment event occurs for a user.
Apache Kafka was a good choice; it is a distributed event store and stream processing platform. Apache Kafka is used extensively on the payment layer. When a user makes a successful transaction like a subscription, after getting notified via the webhook from our payment provider, our backend API, serving as the Apache Kafka "Producer", sends a message to a Kafka topic. The Kafka "Consumers" (Web and Mobile applications) listening to that topic at the time would not get notified of a successful transaction before giving value.
Our setup ended up looking like this:
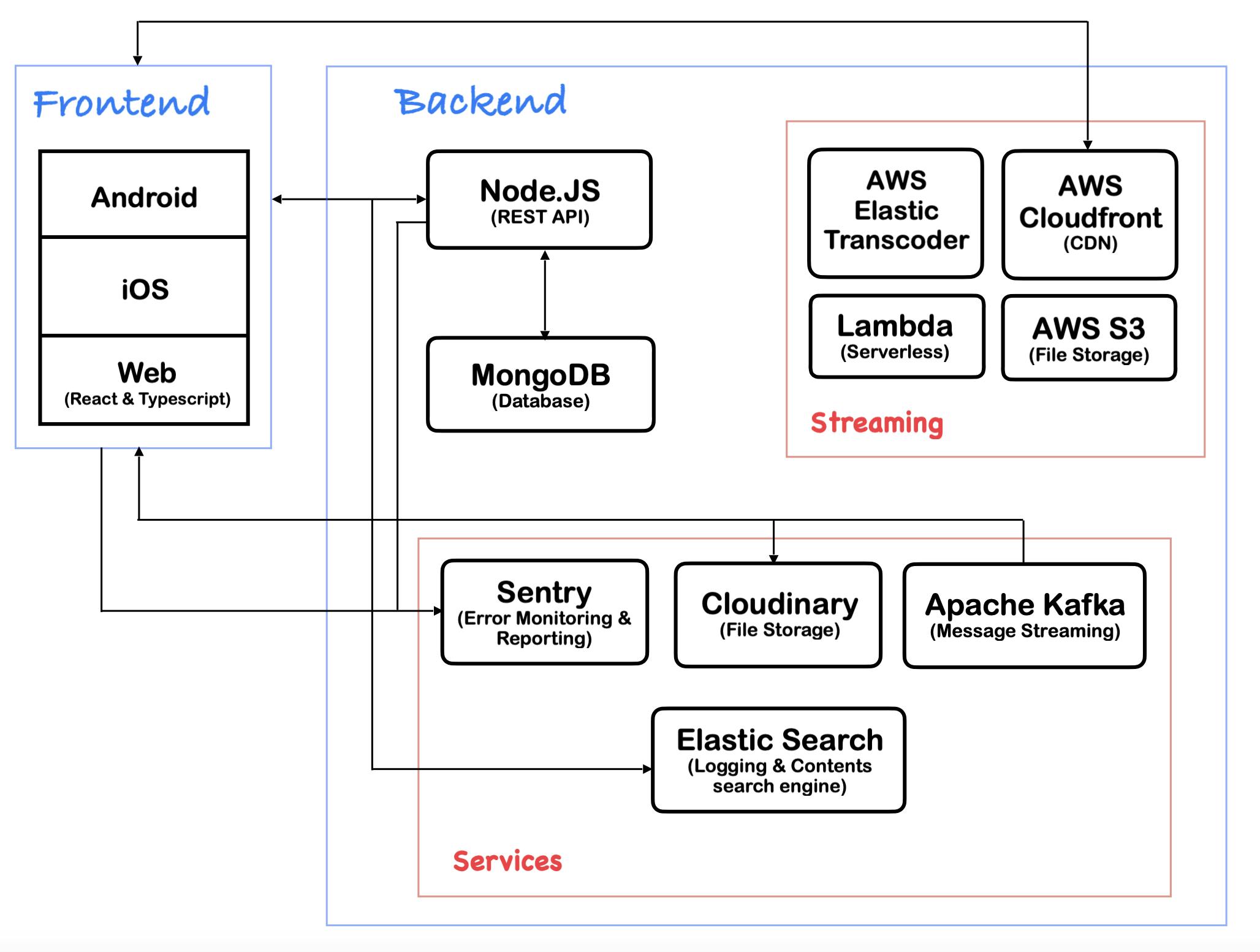
It was a challenging but thrilling experience that took months of practice and learning. It is far from perfect, but so far, streaming worked better compared to when I started. I took advantage of cloud solutions where necessary to ease work and build faster, but this came at a cost: CLOUD SERVICES MAY BECOME VERY EXPENSIVE AS YOUR RESOURCES INCREASE.
In the next part of this series, I'll talk about horizontal scaling, more on security, cache setup and distributing traffic.
Twitter: @PaschalDev